今はやりのPythonを使って、Google検索結果をスクレイピングしてSEOに役立てることができればと思い、実際にスクレイピングを試してみました。
環境は、Windows10 64bit で、Mac OSと違っていろいろ手間取ったり、seleniumでスクレイピングするまでにインストールしなければならないものとかがいろいろあったので、備忘録もかねてやり方を載せておきます。
ここでは、本当の初歩の初歩(Pythonをインストールするところ)から解説しますので、スクレイピング初心者の方にもぜひこの記事を読んで挑戦していただければと思います。
1. Pythonをインストール
まずは、PythonをWindowsにインストールします。
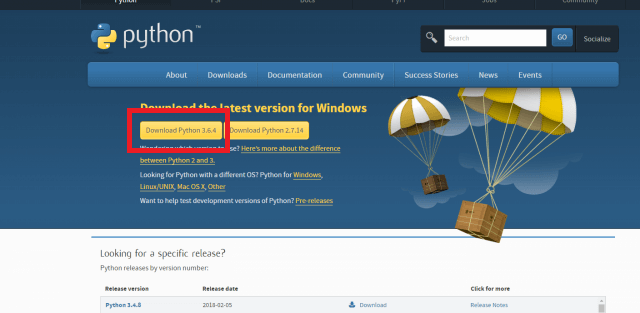
https://www.python.org/downloads/
ここから、最新のバージョンを選んでインストールしてください。
2018年3月27日現在の最新バージョンは「3.6.4」です。
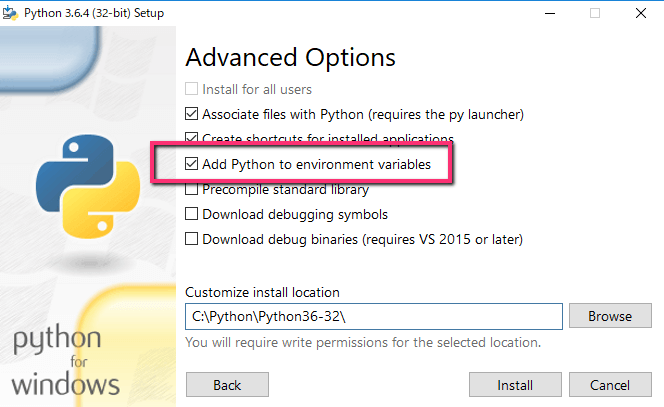
インストール時に「Advanced Options」の「Add Python to environment variables」にチェックを入れましょう。
ここにチェックを入れることで、後々に環境変数PATHを設定することなくコマンドプロンプトやPower ShellでPythonのコマンドを使えるようになります。
2. Seleniumをインストール
Webブラウザ上に表示されている要素を操作するツールであるSeleniumをインストールします。ちなみにこのSeleniumはいろいろな言語で使用することができ、今回はPythonを使っていますがRubyやJavaでも使うことができます。
Googleの検索エンジンは、自動化したロボットで検索クエリを送り続ける行為を禁止しており、この行為をしようとすると検知されて画像確認を行わなければ検索できなくなってしまいます。
今回のプログラムは、一つのキーワードのみで行うため、検索クエリを送り続ける行為にはなりません。もし、プログラムを改変して大量の検索クエリを投げたい場合は、数秒毎の間隔を上げて次の検索クエリを投げるように設定してください。
2.1. Windows Power Shellを起動する
ここから、Windows Power Shellを使っていきます。
Windows Power Shellは、Windows10に既に入っていますので、ダウンロードする必要はありません。
スタートメニュー等からWindows Power Shellを選択してください。
Windows Power Shellを起動したら、
pip install selenium
をコピペして、入力してください。
すると、おそらく
You are using pip version 9.0.1, however version 9.0.3 is available. You should consider upgrading via the 'pip install --upgrade pip' command
というエラーメッセージが表示され、pipをバージョンアップしろと言われるはずです。
この状態で、指示された
pip install --upgrade pip
を入力しても、うまくはいきません。
2.2. Power Shellを管理者権限で起動する
一度、Power Shell自体を管理者権限に権限を上げる必要があり、Macであれば、sudoコマンドを使って簡単にできますが、Windows Power Shellではsudoが使えないので、
Power Shell上に
Start-Process powershell.exe -Verb runas
と入力し、管理者権限で新たにPower Shellを起動します。
すると、管理者権限でPower Shellが新しく立ち上がります。
2.3. pipをアップグレードする
管理者権限のPower Shellに再度pipをアップグレードするコマンドを入力します。
pip install --upgrade pip
2.4. seleniumをインストールする
同じく管理者権限で、seleniumをインストールします。
pip install selenium
ここまでが管理者権限でなければ、インストールできないものでした。
3. ChromeDriverをインストールしてseleniumを動くようにする
seleniumを動かすには、WebDriverが必要になります。
今回は、Chromeを使用するため、ChromeDriverをインストールする手順を紹介しますが、
Firefoxを使いたい場合は、geckodriverをインストールすることになります。
ちなみに、WebDriverをインストールせずにseleniumを動かすと、
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
のようなエラーが表示されます。
このエラーが表示された場合は、WebDriverがインストールされていないので、ここで紹介する手順通りにWebDriverをインストールしてください。
3.1. ChromeDriverを手に入れる
まずは、ChromeDriverを以下のサイトからダウンロードします。

※この記事執筆時の最新版は、ChromeDriver 2.37でした。ご利用するタイミングに合わせて最新のものをご使用ください。
3.2. ChromeDriverを解凍して、任意の場所に配置する
ChromeDriverを配置する場所は、どこでも大丈夫です。
PATHを設定することになるので、わかりやすい場所に配置するのがお勧めです。
今回は、Cドライブ直下に、chromedriverというディレクトリを作成して、このディレクトリにChromeDriverの本体を配置します。
C:\chromedriver
3.3. システム環境変数のPATHにchromedriverを追加する
- Windowsタスクバー左のWindowsアイコンの右側にある検索ボックスに「システムの詳細設定の表示」と打ち込み、「システムのプロパティ」を開く
- 「環境変数」をクリックし、「環境変数」ウィンドウを開く
- 下段の「システム環境変数」の「Path」を選択し、「編集」ボタンをクリックする
- 「環境変数名の編集」ウィンドウの「新規」ボタンを押し、リストの最下段にパスを入力するBOXが現れるので、そこに以下のディレクトリを追加する。
C:\chromedriver - 「OK」ボタンを押して完了
4. Google検索結果をスクレイピングするソースコードをコピペする
それでは、Google検索結果をスクレイピングするプログラムを作成していきます。
まずは、プログラムを保存するフォルダを作成しましょう。
今回は、ドキュメントフォルダの中にProgramというフォルダを作成し、そこにプログラムのソースコードを保存していくことにします。
Power Shellを新規で起動し、
cd documents mkdir Program cd Program touch gscrapy.py touch main.py
と入力してください。
すると、ドキュメントフォルダの中に、Programというフォルダが作成され、その中に、「gscrapy.py」と「main.py」というファイルが作成されているのが確認できます。
「gscrapy.py」をお好きなテキストエディタで開いてください。
それでは、ここにソースコードをコピペしていきます。
今回のソースコードは、https://torina.top/detail/318/のサイトに掲載されているソースを一部変更して利用します。
gscrapy.py
from collections import namedtuple
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
# 検索結果を1件ずつ格納する名前付きタプル
SearchResultRow = namedtuple(
'SearchResultRow',
['title', 'url', 'display_url', 'dis']
)
# 広告を1件ずつ格納する名前付きタプル
AdResultRow = namedtuple(
'AdResultRow',
['title', 'url', 'display_url', 'dis1', 'dis2', 'dis3']
)
# 関連キーワードを1件ずつ格納する名前付きタプル
RelationResultRow = namedtuple(
'RelationResultRow',
['word', 'url']
)
def get_text_or_none(element, num):
"""
のようなHTMLから、テキストを取得する際に使います
for row in driver.find_elements_by_css_selector('div.spam'):
a_element = row.find_elements_by_tag_name('a')
a1 = get_elements_of_one(a_element, 0)
a2 = get_elements_of_one(a_element, 1)
a3 = get_elements_of_one(a_element, 2)
"""
try:
return element[num].text
except IndexError:
return ''
class GoogleScrapy:
def __init__(self, keyword, end=1, default_wait=5):
self.url = 'https://www.google.co.jp?pws=0'
self.keyword = keyword
self.end = end
self.default_wait = default_wait
self.driver = None
self.searches = [[] for x in range(end)]
self.ads = [[] for x in range(end)]
self.relations = [[] for x in range(end)]
def enter_keyword(self):
"""キーワードを入力し、エンターを押す"""
self.driver.get(self.url)
self.driver.find_element_by_id('lst-ib').send_keys(self.keyword)
self.driver.find_element_by_id('lst-ib').send_keys(Keys.RETURN)
def next_page(self):
"""次のページへ移動する"""
self.driver.find_element_by_css_selector('a#pnnext').click()
time.sleep(self.default_wait)
def get_search(self, page):
"""通常の検索結果を取得する"""
all_search = self.driver.find_elements_by_class_name('rc')
for data in all_search:
title = data.find_element_by_tag_name('h3').text
url = data.find_element_by_css_selector(
'h3 > a').get_attribute('href')
display_url = data.find_element_by_tag_name('cite').text
try:
dis = data.find_element_by_class_name('st').text
except NoSuchElementException:
dis = ''
result = SearchResultRow(title, url, display_url, dis)
self.searches[page].append(result)
def get_ad(self, page):
"""広告を取得する"""
all_ads = self.driver.find_elements_by_class_name('ads-ad')
for ads in all_ads:
title = ads.find_element_by_tag_name('h3').text
url = ads.find_elements_by_css_selector(
'h3 > a')[1].get_attribute('href')
display_url = ads.find_element_by_tag_name('cite').text
dis_element = ads.find_elements_by_class_name('ellip')
dis1 = get_text_or_none(dis_element, 0)
dis2 = get_text_or_none(dis_element, 1)
dis3 = get_text_or_none(dis_element, 2)
result = AdResultRow(title, url, display_url, dis1, dis2, dis3)
self.ads[page].append(result)
def get_relation(self, page):
"""関連する検索キーワードを取得します"""
all_relation = self.driver.find_elements_by_css_selector('p._e4b > a')
for relation in all_relation:
word = relation.text
url = relation.get_attribute('href')
result = RelationResultRow(word, url)
self.relations[page].append(result)
def start(self):
""" ブラウザを立ち上げ、各種データの取得を開始する"""
try:
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(self.default_wait)
self.enter_keyword()
for page in range(self.end):
self.get_search(page)
self.get_ad(page)
self.get_relation(page)
self.next_page()
finally:
self.driver.quit()
このソースコードをコピーして貼り付けたら、セーブし、
次は、「main.py」をお好きなテキストエディタで開いてください。
main.py
from gscrapy import GoogleScrapy
google = GoogleScrapy('プログラミング', end=3)
google.start()
print('検索結果 全ページ')
print('-'*30)
for page_num, rows in enumerate(google.searches, 1):
print('-'*30)
print('{0}ページ目'.format(page_num))
print('-'*30)
for row in rows:
print(row.title)
print('-'*30)
print('広告 1ページのみ')
print('-'*30)
for row in google.ads[0]:
print(row.title)
print('-'*30)
print('関連キー 3ページのみ')
print('-'*30)
for row in google.relations[2]:
print(row.word)
これをコピペしてセーブすれば完成です。
スクレイピングを実行する
作ったプログラムを実行して、スクレイピングしましょう。
まずは、Power Shellで、
pwd
と入力し、
「gscrapy.py」や「main.py」が格納されている
Program
のディレクトリ内にいるかどうか確認してください。(さきほど「gscrapy.py」とかをPower Shellで作った後から何も触っていなければ、Programのディレクト内にいるはずなので大丈夫です。)
そして、Power Shellに、
python main.py
と入力し、エンターを押します。
すると、さきほど作ったプログラムが実行され、seleniumに制御されたChromeのテストブラウザーが起動します。(ブラウザーが立ち上がるまで、少し時間がかかります)
そして、自動的にスクレイピングが始まり、
スクレイピング終了後に、Power Shellに実行結果が以下のように表示されます。
検索結果 全ページ ------------------------------ ------------------------------ 1ページ目 ------------------------------ プログラミング (コンピュータ) - Wikipedia プログラミング入門完全版!初心者が基礎から独学で勉強する方法 ... プログラミングとは何か?を世界一わかりやすく解説 | TECH::NOTE ... プログラミング (コンピュータ) - Wikipedia 今更聞けない!プロが教える「プログラミングでできること」って何? | 侍 ... プログラミングとは何か?を専門用語ゼロであらゆる視点から徹底解説 | 侍 ... プログラミング初心者が最初に習得すべきプログラミング言語 | プロナビ プログラミングは何歳までなら習得可能か?|山本 一成@Ponanza|note これからプログラミングを学ぼうとする君へ | Social Change! ------------------------------ 2ページ目 ------------------------------ はじめてのP:第1週:プログラマになる -プログラミングの魅力を学ぼう!1 ... プログラミング 本 | Amazon | アマゾン 世界一わかりやすい! プログラミングのしくみ | サイボウズ, 月刊Newsが ... #プログラミング hashtag on Twitter プログラミングを教えるときの10のポイント (という論文の紹介) – Yu Ukai ... 学習内容 | ディズニー・プログラミング学習教材「テクノロジア魔法学校」 ディズニー・プログラミング学習教材「テクノロジア魔法学校」 ASCII.jp - プログラミング+ IT業界が「プログラミング教育」で立ち上がるべき理由 | Forbes JAPAN ... 「プログラミング」の授業 - Schoo(スクー) ------------------------------ 3ページ目 ------------------------------ Why!?プログラミング [技術 小5~6・中]|NHK for School 池澤あやかさんに聞く「今更ですが、プログラミングって何ですか?」 夏休みにプログラミングを学ぶならLife is Tech ! (ライフイズテック) サマー ... プログラミングスクール|資格・就職に強い【KENスクール】 PyQ - 本気でプログラミングを学びたい人のPythonオンライン学習サービス スタープログラミングスクール|子ども・年長・小学生・中学生の ... プログラミング教材ロボット Proro(プロロ)|Proro(プロロ)とは? プログラミングのレッスン一覧 - プログラミングならドットインストール あそぶ!天才プログラミング / Play! Programming for Geniuses - teamLab 「プログラミング言語かるた 制作プロジェクト」 いよいよ始動! - CAMPFIRE ... ------------------------------ 広告 1ページのみ ------------------------------ 未経験からプログラマーへ就職 | プログラミングを習い高給社員へ ------------------------------ 関連キー 3ページのみ ------------------------------
このプログラム自体はあまり利用価値がありませんが、SEO的なR&D視点でみると、
キーワードを左寄せにした方が1ページ目に上位表示しやすいことがわかりますね。
プログラムを改造して、ページの内容を取得してきたり、形態素解析とつなげて頻出するキーワードや語句を探したり、
データベースとつなげてよりビッグデータ解析とかにもつなげたりできるかと思います。
まとめ
ということで、初歩から自動スクレイピングを行うまで一連の流れを説明してきました。
いかがでしたか?今すぐにでも出来る内容だったかなと思います。
自分の場合は、このSeleniumを使ってとあるアプリをFacebook認証を通ったログインからアプリの自動操作まで勝手にやってくれるプログラム作ったりもしました。
かなり便利で、日常的に役立ってます。
これからの時代は、時間を金で買うのではなく、ロボットを自分で作って時間を作る時代になるのかなと思ってみたり。
Selenium自体は、かなり汎用性の高いツールですので、みなさんもぜひ使い倒してみてください!